
Foto: Tomada de Wired
Chile hizo oficial el lanzamiento de Latam-GPT durante una transmisión en vivo a través de YouTube. El modelo busca “busca construir capacidades propias en inteligencia artificial generativa, promoviendo una gobernanza ética y una arquitectura abierta que respete nuestra cultura y contextos locales”, refleja el sitio web del gobierno de la nación sudamericana.
Este hito se enmarca en una tendencia de lanzar modelos de lenguaje autóctonos, que respeten los códigos nacionales o regionales. La mayoría de herramientas de este tipo se entrenan con un amplio cúmulo de datos y no suelen abarcar realidades de zonas específicas del mundo.
“Es la misma manera de pensar de nosotros con CecilIA y del proyecto español de Salamandra. Tener modelos que sean locales y que representen nuestra manera de hablar, comunidades y cultura. Desde ese punto de vista, es un proyecto muy interesante y le seguimos la pista desde el principio”, dijo el Dr. C. Alejandro Piad Morffis, profesor Titular de la Universidad de La Habana y vicepresidente de la Sociedad Cubana de Matemática y Computación.
Latam-GPT integra 18 terabytes de información en español, portugués e inglés. Se estructuró sobre más de cincuenta alianzas técnicas en quince países de la región. Su desarrollo muestra una articulación entre el Estado chileno, el Centro Nacional de Inteligencia Artificial de Chile, el Banco de Desarrollo de América Latina y el Caribe (CAF) y Amazon Web Services.
El especialista principal de ciudades inteligentes y desarrollo digital del Banco de CAF, Marcelo Faquina, dijo que “Latam-GPT no es solo un desarrollo tecnológico, es una señal concreta de que la región puede trabajar de manera coordinada para desarrollar sus capacidades propias en un ámbito estratégico como la inteligencia artificial”.
“Por primera vez contamos con un modelo de lenguaje de gran escala, construido desde América Latina y el Caribe, capaz de comprender nuestras lenguas, nuestros contextos y sobre todo nuestra diversidad”, añadió.
El Dr. C. Yudivian Almeida Cruz, Director del Grupo de Inteligencia Artificial de la Universidad de La Habana, comentó que “esto refuerza la apuesta y la necesidad de crear modelos gnerativos con un enfoque de soberanía cultural, pero también de colaboración e integración. Latam-GPT se une a una serie de proyectos que ya existen como son Salamandra (España), Amazônia (Brasil), CecilIA (Cuba), KAL (México), entre otros, que potencian el enfoque nuestras maneras de hablar, de crear conceptos, de preservar nuestra historia y tradiciones”.
En la web oficial de Latam-GPT se puede ver un mapa con el progreso de la recolección de datos para pre-entrenamiento por país de la región. Hay 21 naciones en la base de datos, y un total de dos millones 645 mil 500 documentos. El promedio de completitud es del 59,5 por ciento.

En el caso de Cuba, se han recolectado 38 mil documentos, con una tasa de completitud del 42 por ciento.
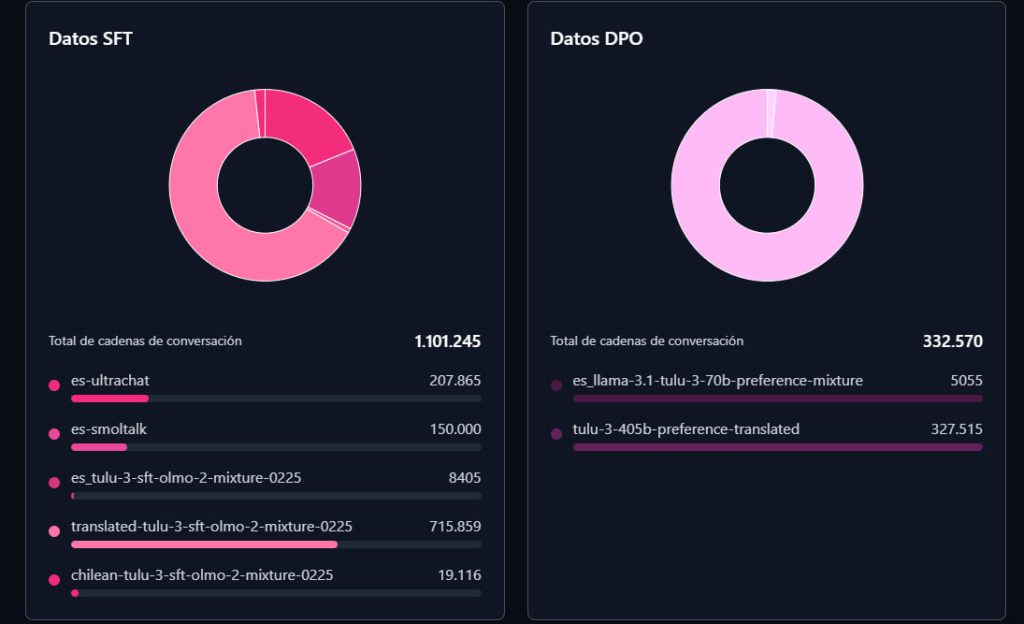
El entrenamiento combina dos fases: primero se enseña al modelo a generar respuestas a partir de conversaciones de ejemplo (SFT), en concreto un millón 101 mil 245 cadenas de diálogo. Después, su comportamiento se refina mediante sistemas de comparación que priorizan las respuestas preferidas por evaluadores humanos (DPO), utilizando otras 332 mil 570 cadenas de conversación.
De momento, no hay ninguna aplicación que permita usar la herramienta. Los creadores de Latam-GPT lanzaron Copuchat, una interfaz de chat interactiva que funciona con la API de OpenAI. El objetivo es recolectar datos que sirvan para entrenar al modelo.
En nuestra breve conversación con Copuchat, detectamos una alucinación con respecto a la literatura cubana. Adjudicó la autoría de La novela de mi vida a Miguel Barnet, una obra de Leonardo Padura. Además, la presentó como basada en la vida del poeta afrocubano Juan Francisco Manzano, cuando es sobre José María Heredia.
“Hay dos formas importantes en que puede haber puntos de contacto con nosotros: podemos ser proveedores de datos con un acuerdo de derechos de autor. Una vez que empiecen a publicar sus modelos, pueden ser base para otros más especializados como CecilIA”, añadió Piad Morffis.
Almeida Cruz comentó que “el intercambio y la colaboración con datos, dadas las asimetrías de infraestructura tecnológica y las distintas formas de creación de modelos, es el principal valor, que no el único, para el desarrollo de modelos nacionales y regionales como lo son Cecilia y Latam-GPT”.
Más que intentar competir con grandes modelos de lenguaje, lo que busca Latam-GPT es llenar algunos vacíos que tienen estos con respecto a Latinoamérica. El cierre de brechas contribuiría a una mayor soberanía tecnológica de la región. Se espera que la primera versión llegue a finales de febrero.
Flash del día

La Comisión Europea ha comunicado a Meta su intención de imponer medidas provisionales para impedir que excluya de WhatsApp asistentes de IA de terceros.
El lunes, la UE informó a la compañía que, en su opinión preliminar, había infringido las normas antimonopolio de la UE. La investigación sigue en curso y las medidas están sujetas a la respuesta de Meta y a su derecho de defensa, según la Comisión.
Prompt de la semana

Avanza en el aprendizaje de un nuevo idioma con este prompt:
“Crea un plan de aprendizaje de [idioma] para mí.
- Nivel actual: [Principiante absoluto/Básico/Intermedio]
- Objetivo: [Conversación/Viaje/Trabajo/Fluidez]
- Tiempo disponible: [15 min/30 min/1 hora] diario
- Estilo de aprendizaje: [Aplicaciones/Videos/Libros/Práctica de habla/Mixto]
- Plazo: [3 meses/6 meses/1 año]
Dame un plan paso a paso con recursos y práctica diaria.”